目录
前言
一句话概括RESTful
一种设计风格,通过URL定位资源,HTTP动词描述操作。旨在让我们更好更快地开发出web应用前后端分离
前后端分离带来的优点
- 可以为多个不同客户端提供同一个数据源不同类型的客户端(pc端,ios端,安卓端)。保证以后开发时,后端代码只要一套即可
- ·可以使得开发url变得更加简洁由之前的get_xx,delete_xx,change_xx,add_xx 之间由一个新的xxs配合请求方法代替
- 可以实现前后端分离,并行开发传统的网络应用程序都是'重服务端',客户端只是单纯的展示数据。即使现在都还是主流;但是由于现在的客户端发展很快,所以现在出现了渐渐着重客户端,旨在减少服务端的职责
实现前后端分离的方法
- 模式1:后台开发先搞好API文档给前端开发。前端开发安装API文档先行写好业务逻辑,但是缺点是前端拿不到测试数据,意味着不能测试逻辑直到真正的API完成后才行。这种模式效率比较低下。
- 模式2:前后端开发做好返回数据类型的约定,前端用假数据模拟这一个后端接口(mock)。这种模式前后端可以并行开发,效率高。但是缺点是要自己编写伪造文件(xx.json),还要启动一个简易服务器模拟(防止跨域),并且完成之后还要删文件,更改请求路径,麻烦。最重要的是只能get不能post
- 模式3:使用第三方工具造假例如mock.js 其原理是拦截掉请求,返回一个造假数据。(也就是说ajax的请求路径可以一开始就写上线版本的)。缺点是无法模拟服务器端记录数据,例如:用户发表一篇博文,然后再发表第二篇
- 模式4:json-server,应该是最好的一种方式只要保证json-server里面的资源和服务器端的资源是一样的,另外都是RESTful风格,就可以无缝切换
RESTful十大规范
协议规范
HTTPS
域名规范
目的是让人一看url就知道这是xx网站请求数据的接口
- 子域名方式
例如:https://www.love.com # 用于给用户访问
https:// api.love.com # 用于请求json数据
注意:该方法需要解决跨域问题,一般用cors解决,表现为一个请求发两次- url方式
例如:https:/ /www.love.com
https:/ /www .love.com/api/
版本表示规范
常用于版本过渡使用
https:// api.example.com/v1/url使用名词
通过url定位资源
即面向资源编程,面向资源编程即是面向一类数据去编程。
现实场景,有很多类数据,例如,产品类、订单类、用户类。每个资源实际上对应一种资源。例如:面向产品类数据编程实际即是面向产品表所记录的数据去编程。面向资源编程最重要是怎样表示资源
即地址即资源(用地址的方式去描述一个资源),看到这个地址,就感觉看到这个地址对应的资源是什么 
http请求动词
对于资源的操作只有增删改查。在HTTP协议中对每一个请求url都会有不同的谓词GET/POST/PUT/PATCH/DELETE,对于每一个代表资源的url配对不同的谓词时会产生不同意义
例如:对 用GET方式去请求,则是请求所有用户数据,换做POST方式,则是要新增一个用户- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
- PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
- DELETE(DELETE):从服务器删除资源。
过滤
如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。通过在url上GET传参的形式传递搜索条件
状态码
- 成功,200系列
200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
204 NO CONTENT - [DELETE]:用户删除数据成功。
- 重定向,300系列
301:临时重定向
302:永久重定向
- 客户端错误,400系列
400 :用户发出的请求有错误,问题在用户的请求,该操作是幂等的。
401 :没有权限(令牌、用户名、密码错误)。
403:权限不够
404:资源不存在,该操作是幂等的。
- 服务端错误,500系列
500 :服务器发生错误
注:实际生产中,状态码与code同时使用,一般和前端讨论时要问前端对状态码有没有要求

错误信息
如果状态码是4xx,就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。
{ error: "Invalid API key"} 请求方法返回
GET /collection:返回资源对象的列表(数组)
GET /collection/resource:返回单个资源对象
POST /collection:返回新生成的资源对象
PUT /collection/resource:返回完整的资源对象
PATCH /collection/resource:返回完整的资源对象
DELETE /collection/resource:返回一个空文档
Hypermedia API
最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。代码上不需要拼接新的链接
例如:访问orders,返回包含全部订单的列表,里面的每一个元素都提供一个获得其详细信息的url
跨域
cors
判断简单请求和复杂请求
1、请求方式:HEAD、GET、POST 2、请求头信息: Accept Accept-Language Content-Language Last-Event-ID Content-Type 对应的值是以下三个中的任意一个 application/x-www-form-urlencoded multipart/form-data text/plain 注意:同时满足以上两个条件时,则是简单请求,否则为复杂请求
预检
对待复杂请求时使用,浏览器会先发一次option请求预检,预检成功之后才发真正要发的请求
因为即使允许指定域名跨域,也会限制不在指定范围内的请求头或请求方法。所以先发一次预检过来验证一下你这个请求头或请求方法能不能被我所接受。from django.utils.deprecation import MiddlewareMixinclass CORSMiddleware(MiddlewareMixin): def process_response(self, request, response): # 添加响应头 # 允许你的域名来获取我的数据 response['Access-Control-Allow-Origin'] = 'http://localhost:8080' # 若是设置cookie跨域,则这里不能为'*' # # 允许你携带Content-Type请求头 response['Access-Control-Allow-Headers'] = """Content-Type,Accept-Encoding,Access-Control-Request-Headers,Access-Control-Request-Method,Connection,Host,Origin,User-Agent,Content-Disposition""" # # 允许你发送DELETE,PUT response['Access-Control-Allow-Methods'] = "GET,POST,DELETE,PUT"
" # 允许使用cookie,使用后,就跟平常没有跨域一样使用。而vue-cookie只是应用在需要我们在在客户端手动操纵cookie的时候 response['Access-Control-Allow-Credentials'] = 'true' return response
跨域cookie
在跨域过程中,Cookie是默认不发送的。就算后端返回Cookie字段,浏览器也不会保存Cookie,更不会在下一次访问的时候发送到后端了。
跨域cookie的设置
第一步,在ajax中设置,withCredentials: true。第二步,服务端的Access-Control-Allow-Origin 不可以设置为"*",必须指定明确的、与请求网页一致的域名第三步,服务端的 Access-Control-Allow-Credentials: true,代表服务器接受Cookie和HTTP认证信息。因为在CORS下,是默认不接受的。- 对于XMLHttpRequest的Ajax请求
var xhr = new XMLHttpRequest();xhr.open('GET', url);xhr.withCredentials = true; // 携带跨域cookiexhr.send(); - 对于JQuery的Ajax请求
$.ajax({ type: "GET", url: url, xhrFields: { withCredentials: true // 携带跨域cookie }, processData: false, success: function(data) { console.log(data); }}); - 对于axios的Ajax请求
axios.defaults.withCredentials=true; // 让ajax携带cookie
代理服务器
有两种方法
正向代理(部署一个和浏览器同源的代理服务器进行转发,例如python中使用request进行转发,),由于服务器端没有同源策略限制,无论怎样的数据都会收到反向代理(让服务器获得指定的同源域名),通过修改Nginx的配置文件,将指定的不同源域名代理到当前服务器一般的代理服务器指的是正向代理,vue的配置如下
vue的config/index.js中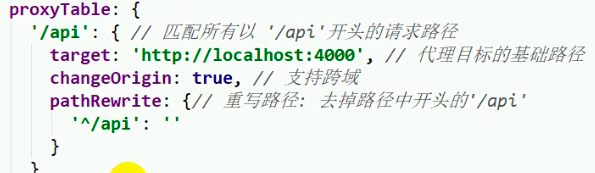
代理服务器的缺点
使用代理服务器的缺点是对不同源资源的转发请求,如果同时多个用户进行跨域请求,因为服务器内部需要进行额外的HTTP请求,那么服务器端的处理压力降会变大,从而导致阻塞等一系列性能问题,如需更好的方案,还是得使用Nginx等反向代理服务器进行端口代理处理。restfulframework
restfulframework是基于Django的一个组件,目的是帮助开发高效开发出RESTful风格的web后端
由于RESTful需要多种不同的请求方法,因此视图模式最好使用CBV实现,因为CBV是基于反射实现的,原理是根据请求方式不同,执行不同的方法。
CBV的流程是:url路由->as_view方法->dispatch(反射,执行其成员函数)restfulframework的APIView是这个组件的核心,继承django基础的View,在这基础上封装了很多诸如认证,权限等小组件。
restfulframework流程如下:请求进来->走dispatch->版本->认证->权限->节流
->借由反射执行视图->借由解析器拿请求数据->借由序列化器进行数据校验->根据业务逻辑拿数据库数据->借由序列化器格式化数据库数据->如果数据量大,借由分页器分页->借由渲染器在浏览器渲染不同的显示除了这些,restframework还有路由组件,视图组件 APiView认证组件的源码剖析第一步:进来就走dispatch
第二步:dispatch里面对原生的request进行进一步封装 第三步:然后执行self.initial(request) 第四步:self.initial里面执行认证self.perform_authticate 第五步:self.perform_authticate执行request.user 第六步:request.user内部将所有的认证类(全局/局部),并通过列表生成式创建认证对象, 第七步:最后遍历取出认证对象并调用其authenticate方法一一进行验证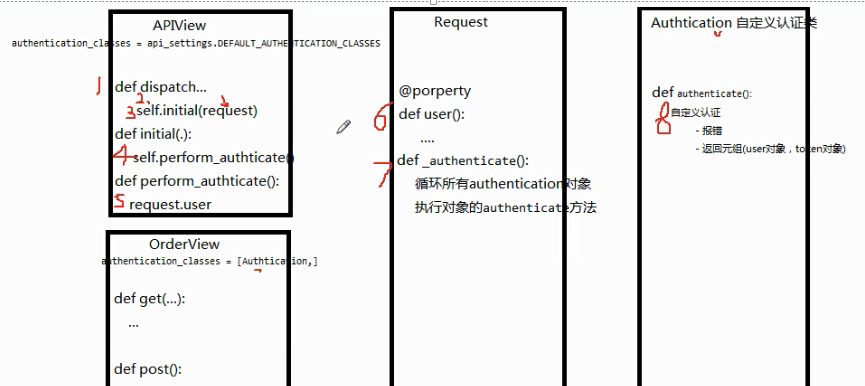
附:使用django-restfulframework注意点
- APIView的处理视图的第一个参数request是已经被rest framework将各种参数加工封装后的request,真正的request这样拿request._request。并且其里面有这样一个机制,当调用request.xx时,xx在request时就直接返回,若没有,则去看看request._request.xx有没有
- APIView的as_view函数返回一个csrf_exempt (view),换句话说已经取消django默认的csrf验证方式。
- postman的一个标签相当于一个浏览器
认证组件
首先要了解,在分布式系统中,必须要重新考虑“登录凭证”的问题。因为session共享的处理十分麻烦。
所以大多数都采用jwt的认证方式,即登录成功后返回一个token作为用户的认证票据,可以放在请求头或者url GET参数中带过来进行验证token的常见处理是,在数据库中定义一个新的表来存储。以用户OnetoOne关联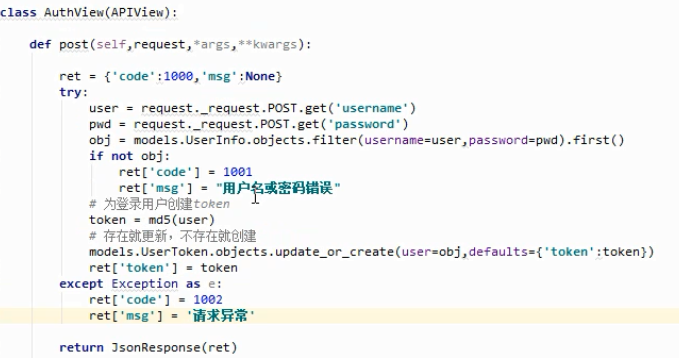
好,进入正题,restfulframework提供认证组件,这让开发者省去写装饰器或者中间件去验证用户认证票据的流程。开发者只需要定义符合指定接口的认证类,配置上即可使用。
- 默认情况下
如果不指定任何的认证类,默认是
'DEFAULT_AUTHENTICATION_CLASSES'= ( 'rest_framework.authentication.SessionAuthentication', 'rest_framework.authentication.BasicAuthentication' ),# SessionAuthentication对通过login(request,user)登录的用户有CSRF检测。# BasicAuthentication很多老牌路由器登录的方法。方式是使用浏览器自带的"对话框”方式将用户名密码经过base64加密后放在请求头里面发过去 现在基本被淘汰,直接写在配置上没有任何反应。
- 认证组件大体使用流程
- 定义一个Authtication类继承 BaseAuthentication
- 其内部覆写一个authenticate方法,在里面进行验证流程
- 在APIView子类里声明authentication_classes =[Authtication,] 即可使得当前的APIView生效
- 或者也可以在settings.py配置全局生效
REST_FRAMEWORK = { # 全局使用的认证类 "DEFAULT_AUTHENTICATION_CLASSES":['api.utils.auth.FirstAuthtication', ], #覆盖框架定义全局认证类 # "UNAUTHENTICATED_USER":lambda :"匿名用户" "UNAUTHENTICATED_USER":None, # 匿名,request.user = None "UNAUTHENTICATED_TOKEN":None,# 匿名,request.auth = None} - 认证类编写细节
from rest_framework.authentication import BaseAuthenticationfrom rest_framework import exceptions class UserAuth(BaseAuthentication): def authenticate(self, request): token = request.query_params.get("token") usertoken= UserToken.objects.filter(token =token).first() if usertoken: # 只能返回None或指定元组,一旦其中一个认证对象返回了元组,则整个认证流程结束 return usertoken.user, usertoken.token else: raise AuthenticationFailed({ "code":1001,"error":"用户认证失败"}) # raise AuthenticationFailed("认证失败!") # restframework内部会有专门的捕捉,并返回 def authenticate_header(self,request): # 编写当认证失败时给浏览器返回的响应头 pass
注意:认证类的authenticate返回
- 若验证成功,返回一个‘规定’的元组。元组的第一个元素给APIView里面的request.user;第二个元素给APIView里面request.auth,一般为token
- 若返回None,表示让下一个验证继续处理
- 注意若全部认证类都返回None,则框架会默认给request.user赋予AnonymousUser,request.auth 赋予None
- 可以在setting.py文件里配置,当全部认证类都返回None时,默认最终返回什么

权限组件
- 权限组件也是跟认证组件一个机制
- 局部配置:permission_classes = [MyPermission1, ]
- 全局适用:
REST_FRAMEWORK = {"DEFAULT_PERMISSION_CLASSES":['api.utils.permission.SVIPPermission']} - 编写细节
from rest_framework.permissions import BasePermission class SVIPPermission(BasePermission): #按规范 需要继承BasePermission message = "必须是SVIP才能访问" def has_permission(self, request, view): if request.user.user_type != 3: return False return True
注意权限类的两个方法:
1.has_permission has_permission只能返回True和False,True表示轮到下一个权限对象检查,False表示这个权限检查不通过,终止检查流程返回当前的Message信息。 自定权限类的has_permission若返回False会触发异常,框架内部会捕捉异常并返回一个message信息。
2.针对GenericViewSet的 has_object_permission
权限检查有一个def has_object_permission(self, request, view, obj): 这个是用户检查用户是否有操作这个对象obj的权限(粒度更小) 这个调用时机是在,GenericViewSet(其实是GenericView)的get_object里面有一个check_object_permissions,他循环调用了权限检查对象的has_object_permission检查是否对这个对象有操作权限。 换句话说,也就是在使用GenericViewSet,才会使得has_object_permission起作用
频率访问限制组件
- 局部:throttle_classes=[]
- 全局:"DEFAULT_THROTTLE_CLASSES":["api.utils.throttle.UserThrottle"] ,注意:这里的是全局的api函数共享一个频率
- 编写细节:实现1分钟只能访问3次
#VISTIT_RECORD字典可以用django缓存替换 import time VISIT_RECORD = {} class VisitThrottle(BaseThrottle): def __init__(self): self.history = None def allow_request(self,request,view): # 1. 获取用户IP remote_addr = self.get_ident(request) ctime = time.time() if remote_addr not in VISIT_RECORD: VISIT_RECORD[remote_addr] = [ctime,] return True history = VISIT_RECORD.get(remote_addr) self.history = history while history and history[-1] < ctime - 60: history.pop() if len(history) < 3: history.insert(0,ctime) return True # return True # 表示可以继续访问 # return False # 表示访问频率太高,被限制 def wait(self): # 还需要等多少秒才能访问 ctime = time.time() return 60 - (ctime - self.history[-1])
注意:throttle_classes=[] ,allow_request返回True或False,True表示交给下一个频率类对象检查,False表示检查不通过,终止检查流程并返回当前的wait函数所返回的提示时间。
- 内置限流类SimpleRateThrottle
频率访问的内置类非常精彩,有一个SimpleRateThrottle通过在配置文件里面设置相应的频率,内部即可实现。还有它的wait方法提供了倒数功能
- 首先继承SimpleRateThrottle并定义变量scope作为频率配置的key
- 然后,覆写 get_cache_key(self, request, view) ,要返回去字典中取值时候的用户标识,一般为ip地址,所以可以直接返回 self.get_ident(request)
AnonRateThrottle:用户未登录请求限速,通过IP地址判断UserRateThrottle:用户登陆后请求限速,通过token判断from rest_framework.throttling import BaseThrottle, SimpleRateThrottleclass AnonRateThrottle(SimpleRateThrottle): scope = "Anon" def get_cache_key(self, request, view): # 返回查找键值 return self.get_ident(request)class UserRateThrottle(SimpleRateThrottle): scope = "User" def get_cache_key(self, request, view): return request.user.username
- settings.py配置
REST_FRAMEWORK = { 'DEFAULT_THROTTLE_CLASSES': ( 'rest_framework.throttling.AnonRateThrottle', 'rest_framework.throttling.UserRateThrottle' ), 'DEFAULT_THROTTLE_RATES': { 'anon': '100/day', 'user': '1000/day' }}# DEFAULT_THROTTLE_RATES 包括 second, minute, hour, day
版本处理
一般不需要自己编写类,只要根据自己版本表示的形式在settings.py配置好即可
目的是可以在视图方法中轻松地用request.version获取版本附加了一个锦上添花的request.versioning_scheme。这货可以帮助反向生成当前视图版本的其他urlrequest.versioning_scheme.reverse(viewname='index',request=request)。版本表示的形式- 以GET参数形式(小众)versioning_class = QueryParameterVersioning #注意,这里不用列表了
- 在url中传参(大众)versioning_class = URLPathVersioning注意:使用这个需要和url正则配套使用
urlpatterns = [url(r'^(?P
[v1|v2]+)/users/$', views.UsersView.as_view()),]
setting.py配置
# 配置允许的版本,版本参数key,和默认的版本 REST_FRAMEWORK = {"DEFAULT_VERSIONING_CLASS":"rest_framework.versioning.URLPathVersioning","DEFAULT_VERSION":'v1',"ALLOWED_VERSIONS":['v1','v2'],"VERSION_PARAM":'version',} 解析器
一般不需要自己编写类,只要根据自己版本表示的形式在settings.py配置好即可
解析器的本质是根据请求头Content-Type的不同让不同的解析器去处理
为的是可以轻松使用request.data(request.body数据的转换)轻松获得传过来的数据,一般解析完成后为字典形式一般为JSONParser,FormParserfrom rest_framework.parsers import JSONParser,FormParser parser_classes = [JSONParser,FormParser,]#JSONParser:表示只能解析content-type:application/json头,content-type:application/json头表示数据是json格式#FormParser:表示只能解析content-type:application/x-www-form-urlencoded头
文件上传解析器
- MultiPartParser
FileUploadParser只适用于单文件上传,若要夹带另外数据则应该是 parser_classes = [FormParser, MultiPartParser]
分别从request.data和request.FILES中获得- FileUploadParser
FileUploadParser只适用于单文件上传,若要夹带另外数据则应该是
c. FileUploadParser 对于request.FILES和request.data的数据都是一样的如果调用FileUploadParser时,有传入filename参数,就使用其作为filename 如果url中没有设置filename参数,那么客户端在请求头中就必须设置Content-Disposition,例如Content-Disposition: attachment; filename=upload.jpga. let headers = {
// 'Content-Type': 'application/x-www-form-urlencoded', 'Content-Disposition': `attachment; filename=${content.file.name}` }序列化器
序列化器可以做数据校验和queryset的序列化显示
数据校验
- 定义普通版
from rest_framework import serializersclass UserSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField()
# 自定义验证字段,要么返回原值value,要么报错def validate_xxx(self,value): # from rest_framework import exceptions # raise exceptions.ValidationError('字段验证不通过') return value
ModelSerializer版
class UserInfoSerializer(serializers.ModelSerializer): class Meta: model = models.UserInfo # fields = "__all__" fields = ['id','username','password','oooo','rls','group','x1'] depth = 0 # 0代表只去当前自己层去取,数字越大,就往foreignkey 或 manytomany 取出相应的字典形式数据
- 使用
class UserGroupView(APIView): def post(self, request, *args, **kwargs): ser = UserGroupSerializer(data=request.data) if ser.is_valid(): print(ser.validated_data['title']) else: print(ser.errors) return HttpResponse('提交数据')
序列化处理
序列化和之前序列化的对比

序列化的字段处理,主要讲model里特殊字段的处理
- 带choice参数字段处理
使用source参数(source参数可以是指向要序列化对象__dict__里的任意一个,框架内部会根据source利用反射查找)。
当存在source参数时,Serializer类变量的变量名就可任意定义了。source参数可以是函数名,但是该函数不能带参数,其框架内部用iscallable检查是否可以调用,如若可以,序列化时调用返回 
- 外键字段Foreign显示
- 外键字段也是利用source参数
- 值得注意的是序列化字段的是根据最终要序列成的类型而进行定义例如:serializers.CharField(source='role.title') # 外键字段的title最终显示的是字符串(CharField)
- MamyToMany字段处理
- 通过source也是可以做的,但是做不到特别细的粒度|例如:lovers = serializers.CharField(source='lover.all')
- 要使用自定义显示才行
rls = serializers.SerializerMethodField() # 自定义显示def get_rls(self, row): #函数名如同form的clean_xx一样都是配对字段的。get_xx role_obj_list = row.roles.all() ret = [] for item in role_obj_list: ret.append({ 'id':item.id,'title':item.title}) return ret #返回的是字段要显示的
3. 还可以定义自己的Field,覆写to_representation,该方法返回字段对应的序列化结果

-
- 注意:继承哪个字段类型都行,因为覆写to_representation这个方法(输出最后的结果)
- 返回任何类型的结果都行
- 参数value是经source参数反射取出的结果
- 生成hypermedilalink
1.lookup_field 替代了source来进行反射查找,并且这个参数使用'_'分割
2.使用时要在serilizer对象初始化时加入context={'request':request}url(r'^(?P
[v1|v2]+)/group/(?P \d+)$', views.GroupView.as_view(),name='gp') #测试url class UserInfoSerializer(serializers.ModelSerializer): group = serializers.HyperlinkedIdentityField(view_name='gp',lookup_field='group_id',lookup_url_kwarg='xxx') class Meta: model = models.UserInfo # fields = "__all__" fields = ['id','username','password','group','roles'] #extra_kwargs={'user':{'min_length':6},'password':{'validators':[xxxx,]] #验证时候添加,xxx是指定的函数对象 depth = 0 # 0 ~ 10
分页组件
- 原生普通分页看第n页,每页看多少数据,以及指定对应的GET参数,注意这些GET参数可以设为None,表示取消相应的功能settings配置对PageNumberPagination有效
REST_FRAMEWORK = { #分页 "PAGE_SIZE":2 #每页显示多少个}当然我们也可以自己继承PageNumberPagination,在类里面定义
class MyPageNumberPagination(pagination.PageNumberPagination): page_size = 5 max_page_size = 10 page_size_query_param = 'size' page_query_param = 'page' ○ 使用 def get(self, request, *args, **kwargs): # 测试分页对象 from rest.utils.pagination import MyPageNumberPagination from rest.utils.FormSerializer import RoleFormSerializer roles = models.RoleInfo.objects.all() # 创建分页对象 pager = MyPageNumberPagination() # pager = pagination.PageNumberPagination() # 需要在setting里配置,不然没数据 # 在数据库中获取分页的数据 data_list = pager.paginate_queryset(queryset=roles, request=request, view=self) # data_list 已经是roleinfo对象列表,接下来序列化 ser = RoleFormSerializer(instance=data_list, many=True) return Response(ser.data)
- 偏移分页 指定位置,看这个位置的后的第n条数据,以及指定的对应的GET参数
#继承主要是改变max_limit最大大小 class MyOffsetPagination(pagination.LimitOffsetPagination): default_limit = 2 # 默认每页大小 max_limit = 5 # 人工指定的最大大小 limit_query_param = 'limit' offset_query_param = 'offset' a. 使用 def get(self, request, *args, **kwargs): roles = models.RoleInfo.objects.all() pager = MyOffsetPagination() data_list = pager.paginate_queryset(queryset=roles, request=request, view=self) ser = RoleFormSerializer(instance=data_list, many=True) return Response(ser.data)
-
游标分页
加密分页,只有上一页和下一页功能# 特殊的是要设置ordering和返回时是用专用的方法 class MyCursorPagination(pagination.CursorPagination): ordering = '-id' # 一定要设置好排序规则 page_size = 5 max_page_size = 10 page_size_query_param = 'size' cursor_query_param = 'cursor' • 使用 from rest.utils.pagination import MyCursorPagination pager = MyCursorPagination() data_list = pager.paginate_queryset(queryset=roles, request=request, view=self) ser = RoleFormSerializer(instance=data_list, many=True) return pager.get_paginated_response(ser.data) # 使用游标分页特殊的方法返回
视图组件
复杂逻辑 GenericViewSet 或 APIView
增删改查:ModelViewset增删 CreateModelMixin,DestroyModelMixin,GenericViewSet
- GenericViewSet
改变请求方式对应的调用函数,要通过对as_view({'get':'list'','post':'add'})传参
注意:但凡支持{‘get’:’list’}这种as_view传参,就代表其继承了ViewSetMixin。所以class MyView(ViewSetMixin,APIView) 替代GenericViewSet 改变请求方式调用的视图函数这个在多个url对应一个CBV时有奇效。
- mixins.ListModelMixin
增删改查组件,以多继承的方式使用
如 mixins.ListModelMixin里面有一个list函数,它提供了像上面一样的用法,即显示一个对象集合from rest_framework import mixins class RolesView3(viewsets.GenericViewSet, mixins.ListModelMixin): queryset = models.RoleInfo.objects.all() serializer_class = RoleFormSerializer pagination_class = MyPageNumberPagination
- ModelViewSet
继承了GenericViewSet,并集齐了增删改查,局部更新组件
注意:url一定要有一个命名正则pkurl(r'^(?P[v1|v2]+)/role/(?P \d+)/$',RoleView.as_view({ 'get': 'retrieve', 'delete': 'destroy', 'put': 'update', 'patch': 'partial_update'}),name='role'),
由于url的增加和查看,所以一般定义两个url,一个针对象集合,一个针对单一对象的操作
#视图只需一个,url两个 class RoleView(viewsets.ModelViewSet): queryset = models.RoleInfo.objects.all() # 直接传入全局对象,框架内部会根据传入的pk返回单一对象 serializer_class = RoleFormSerializer pagination_class = MyPageNumberPagination
路由组件
当出现这么一个需求:在url后面.json,使得渲染器显示原生的的json数据
我们的解决方案是,有定义两条url配合渲染器达到效果url(r'^(?P[v1|v2]+)/roles4/$',RolesView4.as_view({ 'get': 'list', 'post': 'create'}), name='roles4'), url(r'^(?P [v1|v2]+)/roles4\.(?P \w+)$', RolesView4.as_view({ 'get': 'list', 'post': 'create'}), name='roles4'),
或者定义一条url达到效果
url(r'^(?P[v1|v2]+)/roles4(\.(?P \w+))?$',RolesView4.as_view({ 'get': 'list', 'post': 'create'}), name='roles4'),
路由组件提供全自动路由
所谓全自动,指不用再as_view指定组件的指定函数名称,而且还生成了.json后缀,自动生成单一对象和对象集合的4组url 使用场景:单一个api对一个表进行简单的增删改查(配合ModelViewset)用得多,但是单单的增删功能就没有必要了# 以下写在url文件里from rest_framework import routersrouter = routers.DefaultRouter()router.register(r'xxxx', views.RouterView) # xxxx代表url标志符 urlpatterns = [ url(r'^(?P[v1|v2]+)/', include(router.urls)),#注意: xxxx代表url标志符,在指定前缀正则('^(?P [v1|v2]+)/)后面添加# http://127.0.0.1:8000/api/v1/xxx/
渲染器
一般配置在settings.py里,目的是配置浏览器如何显示json(为了页面更好看)
from rest_framework import renderersrenderer_classes = [renderers.JSONRenderer, renderers.BrowsableAPIRenderer, renderers.AdminRenderer]# 例如使用 admin渲染器:http://127.0.0.1:8000/api/v1/roles4/?format=admin